
伴隨著“中國制造”,“中國創造”走向世界,漢之光華將以卓越的
服務能力協助我們的客戶完成全球知識產權布局。



【前 言】
2024年7月,世界知識產權組織WIPO發布了《生成式人工智能專利態勢報告》(以下簡稱:WIPO報告),報告分析了從2014年至2023年底的十年間,全球生成式人工智能(GenAI)相關專利情況,并給出了權威的結論。《WIPO報告》顯示,在這10年間,全球GenAI相關專利申請有5.4萬件,其中中國的專利申請量以3.8萬件占據首位,遠遠超過美國、韓國、日本和印度等國。由于 GenAI 技術呈現井噴式發展,相應的專利申請量也呈現指數式上升,僅2023年公布的 GenAI 相關專利就超過了全部總數的1/4。相應地,GenAI技術淘汰速度也非常快,可以想見過去10年的專利技術,越是新的技術越是具有參考借鑒價值。
本文將沿襲《WIPO報告》的專利分析思路,聚焦ChatGPT發布后,即2023年1月以后公開的GenAI幾個最主要的大模型相關專利數據進行分析,為感興趣的客戶提供參考。
關注的大模型有:
1. 生成對抗網絡Generative adversarial networks (GAN)
2. 變分自編碼器 Variational autoencoders (VAE)
3. 基于解碼器的大型語言模型 decoder-based large language models (decoder-based LLM)
4. 自回歸模型 Autoregressive models(AM)
5. 擴散模型 Diffusion models(DM)
《WIPO報告》顯示,在其調研的過去10年間的 GenAI 大模型專利中,大多數專利屬于GANs。
2014年至2023年間,GANs大模型的專利家族有9700個,僅2023年就有2400個專利家族公布。VAEs和LLMs的專利家族數量分列第二和第三位,2014年至2023年間分別擁有約1800和1300個新專利家族。
在專利增長方面,GANs專利在過去十年中增長最為強勁。然而,最近這一速度有所放緩。相比之下,擴散模型(DMs)和 LLMs 在過去三年中顯示出更高的增長率,擴散模型的專利家族數量從2020年的18個增加到2023年的441個,LLMs的專利家族從2020年53個增加到了2023年881個。顯然ChatGPT 等現代聊天機器人引發的 GenAI 熱潮增加了人們對 DMs和LLMs大模型的研發投入。
一、GenAI 大模型的前世今生
2022年11月,OpenAI 推出了聊天生成預訓練轉換器(ChatGPT),并且迅速爆火。該產品以強大的文字處理和人機交互功能迅速風靡全球。以ChatGPT 等大語言模型為標志的生成式AI 的成功,帶來了新的范式革命和廣闊的商業前景,資本市場持續高漲的熱情也足以彰顯它的價值。當然,ChatGPT等大語言模型也不是橫空出世的,以下我們簡單了解一下生成式AI的前世今生。
“GenAI+大模型”是一個結合了生成式人工智能(Generative AI)和大型語言模型(Large Language Model, LLM)的先進概念。生成式人工智能(Generative AI,簡稱 GenAI)是一類能夠生成新內容(如文本、圖像、音頻等)的人工智能技術。它通過學習和理解大量數據來模擬人類的創造力。大型語言模型(Large Language Model)是自然語言處理領域中的一種深度學習模型,具有數以億計的參數,能夠理解和生成自然語言文本。這些模型通常通過大規模語料庫的訓練來提高性能。
生成式AI技術于2010年代初開始出現,當時的變分自動編碼器(VAE)成為第一個廣泛用于生成逼真圖像和語音的深度學習模型。自動編碼器的工作原理是將未標記的數據編碼為壓縮表示,然后將數據解碼回其原始形式。普通自動編碼器可應用于多種用途,包括重建損壞或模糊的圖像。變分自動編碼器不僅增強了重建數據的關鍵能力,而且還可以輸出原始數據的變化形式。
這種生成新數據的能力引發了一系列新技術的快速發展,從生成式對抗網絡(GAN)到擴散模型,這些技術能夠生成更加逼真的虛構圖像。因此,變分自動編碼器為當今的生成式AI奠定了基礎。變分自動編碼器基于編碼器和解碼器塊構建而成,這種架構也是當今大語言模型(LLM)的基礎。具體來說,編碼器將數據集壓縮為密集表示形式,在抽象空間中將相似的數據點排列得更緊密。解碼器從這個抽象空間中進行采樣以創建新內容,同時保留數據集的最重要特征。
Transformer將“編碼器-解碼器”架構與文本處理機制相結合,于是形成了基于解碼器的大型語言模型(decoder-based LLMs)。編碼器將原始文本轉換為“嵌入”表示。解碼器將這些嵌入與模型之前的輸出相結合,并連續預測句子中的每個單詞。通過填空猜謎游戲,編碼器可以了解單詞與句子之間的關系,而無需任何人標記詞性。Transformer甚至可以在未制定特定任務的情況下進行預訓練。學習這些強大的表示之后,就可以使用更少的數據來增強模型的專業化水平,以便執行給定的任務。Transformer因其全面多樣的功能而被稱為基礎模型。基礎模型在理論上可以應用于許多領域,因而提供了加速和擴大生成式AI采用的機會。例如,大規模參數的LLM可以改變整個組織中的信息生成和共享方式。參數是在訓練時使用的變量,有助于推斷新內容。只需對LLM進行適當調整,以適應語義搜索、分類、預測、摘要生成和翻譯等任即可。基礎模型的采用得到了一系列主流的新興AI工程最佳實踐的支持,從模型開發到快速工程,這些通用實踐和方法大幅簡化了整個企業和生態系統的協作。基礎模型需要大量的計算、存儲和網絡資源,會消耗大量的能源。只有經過持續不斷的實驗和迭代才有可能取得成功。
自回歸模型(AM)是一種概率模型,通過對給定序列中在先觀測的每個條件概率進行建模,來描述觀測序列的概率分布。換句話說,自回歸模型通過考慮先前的值來預測序列中的下一個值。在GenAI的背景下,自回歸模型通常用于生成新的數據樣本。自回歸模型適用于語言生成、圖像合成和其他生成任務。自回歸模型在應用于自然語言處理任務(例如,大多數現代LLM,如GPT-3或GPT-4是自回歸的)和圖像生成任務(如PixelCNN)時特別成功。因此可以認為 AM 大模型是和LLM大模型配合使用的。
擴散模型的靈感來自擴散的概念,擴散在物理學中用于模擬一組粒子在兩個不同物理區域中的運動。用于圖像生成的擴散模型涉及一個神經網絡,用于預測和去除給定噪聲圖像中的噪聲。生成過程相當于首先對圖像應用隨機噪聲(隨機像素),然后迭代使用神經網絡去除噪聲。隨著噪聲的逐漸消除,一個新穎而有意義的圖像被構建出來,由額外的機器學習機制控制,如圖4所示。近年來,擴散模型取得了長足的進步,現在對于文本到圖像的生成非常成功,例如穩定擴散(Rombach等人,2021)和DALL-E模型家族(OpenAI 2021)。
生成對抗網絡(GAN)是Goodfellow等人于2014年提出的一種用于任務生成的深度學習模型。GAN由兩部分組成,生成器(Generator)和判別器(Discriminator)。生成器是一個生成輸出圖像的神經網絡,判別器一個評估生成器生成的圖像真實度的神經網絡。生成過程是這兩部分之間的競爭。生成器改進其輸出以誤導判別器,判別器試圖提高其區分真實圖像和生成圖像的能力,以避免被生成器誤導。因此,生成器將最大限度地提高其生成逼真圖像的能力。如今,GAN用于許多涉及圖像的任務,如生成和增強照片級真實感圖像。
二、ChatGPT發布后GenAI大模型的發展
為了更好地了解最新的 GenAI+大模型 的技術發展情況,基于《WIPO報告》的專利分析思路,聚焦 ChatGPT 發布后,即2023年1月以后全球公開的 GenAI 幾個最主要的大模型相關專利數據,了解這方面全球最新的研究成果。本文中所研究的專利是根據專利摘要、權利要求或標題中的信息,可以明確屬于哪個大模型的 GanAI 相關專利,這和《WIPO報告》的專利篩選規則一致。但是由于所用數據庫的不同造成了檢索式略有不同,因此檢索命中數量也略有不同,但是沒有本質變化,不會影響分析結論。
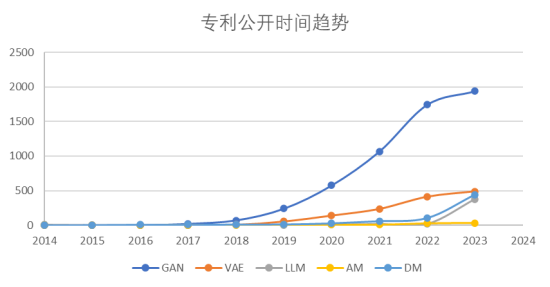
圖1 2014-2023年GenAI大模型相關專利公開時間趨勢
從圖 1 各大模型公開趨勢圖可以清晰的得知 GAN 在近10年增長最為迅猛,但是2022年后增長有所放緩;與之相反,2022年后 LLM 和 DM 專利公開量一改過去零星的申請量,其全球申請量呈現了迅速攀升的態勢。可見在OpenAI公司推出ChatGPT的同時,即在2022年,GAN,LLM,DM 的專利申請趨勢已經發生了異動,研發熱點已經順應市場應用的需求發生了轉向。GhatGPT 并非橫空出世的,而是順勢而為,在眾多研發實體推出的解決方案中脫穎而出,從而引領了之后的研發方向。
另外 VAE 相關專利的公開量則在近10年呈現緩慢的增長態勢,AM 相關專利則一直只有零星的申請量。可見 VAE和AM兩個大模型和當今最熱的 GenAI 應用場景并不特別相關。
GAN,LLM,DM 這3種大模型的技術發展和應用受到 ChatGPT 帶來的 AI 技術轉向的深刻影響。我們非常有必要進一步研究ChatGPT發布后(2023年1月1日~2024年6月30日)各大模型的公開量(見圖 2)。
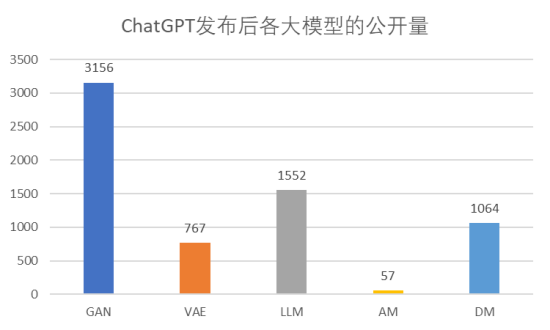
圖2 ChatGPT發布后各大模型的公開量
圖2給出了各大模型在ChatGPT發布后(2023年1月1日~2024年6月30日)的全球相關專利的公開量。雖然 GAN 相關專利的公開量的增長有所放緩,但是 GAN 相關專利公開量仍然是 LLM 相關專利的兩倍。受 GhatGPT 的發布影響非常少的大模型 VAE 和 AM 在這段時間的申請量非常少,尤其是 AM 近10年來專利申請量一直都非常少,可以預見在未來沒有新的技術方向涌現的情況下,AM 大模型將依然并不是最主要的模型。
當然,這里必須指出,根據專利標題、摘要以及權利要求等信息,將5種不同的大模型的相關專利分配在不同組的方法也是有缺陷的,所有GenAI專利家族中有很大一部分不適合任何特定的大模型。許多GenAI專利的標題、摘要以及權利要求不包含特定的大模型關鍵字,而是專注于描述專利的應用,并且在專利說明書里面只對使用的GenAI過程進行了一般性描述。這使得我們很難將一些專利映射到五個核心GenAI模型,同時這5種不同的大模型在技術解決方案上也有一些重疊。
因此以上分析方法可能帶來一些信息失真,我們非常有必要進一步結合應用領域、大模型訓練/處理的數據類型、以及知名GenAI技術研發主體進行深入分析,以獲得更加有意義的參考信息。敬請期待!





